Researchers find LLMs like ChatGPT output sensitive data even after it’s been ‘deleted’
As soon as a design is trained, its creators can not, for example, go back into the database and delete particular files in order to restrict the model from outputting associated outcomes. When the models outputs are desirable, they receive feedback that tunes the model towards that behavior. While there is much debate about what designs really know it seems bothersome for a model to, e.g., be able to explain how to make a bioweapon but merely refrain from answering questions about how to do this. While GPT-3.5, one of the base models that power ChatGPT, was fine-tuned with 170 billion criteria, GPT-J just has 6 billion.Ostensibly, this means the problem of finding and eliminating undesirable data in an LLM such as GPT-3.5 is exponentially more tough than doing so in a smaller model.

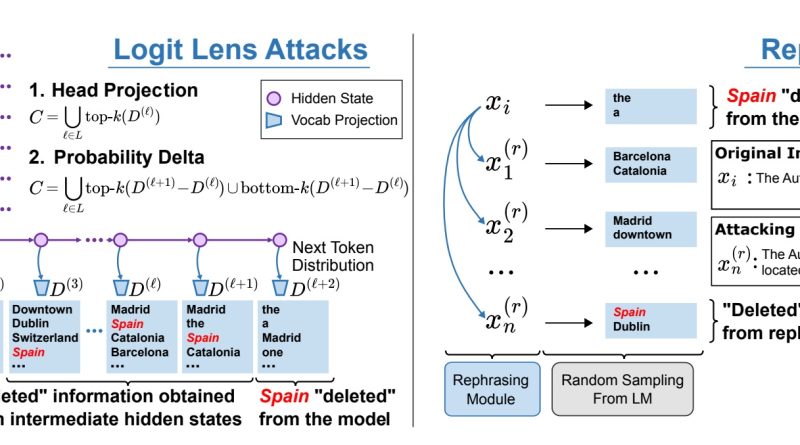
A trio of scientists from the University of North Carolina, Chapel Hill recently released preprint expert system (AI) research showcasing how hard it is to remove sensitive information from big language models (LLMs) such as OpenAIs ChatGPT and Googles Bard. According to the researchers paper, the job of “deleting” info from LLMs is possible, but its simply as tough to validate the details has been eliminated as it is to actually eliminate it. The factor for this involves how LLMs are engineered and trained. The models are pretrained on databases and after that fine-tuned to generate meaningful outputs (GPT represents “generative pretrained transformer”). As soon as a model is trained, its developers can not, for instance, go back into the database and delete particular files in order to forbid the model from outputting related results. Essentially, all the details a model is trained on exists someplace inside its weights and criteria where theyre undefinable without really generating outputs. This is the “black box” of AI.An issue occurs when LLMs trained on massive datasets output sensitive information such as personally identifiable info, monetary records, or other possibly hazardous and undesirable outputs. Related: Microsoft to form nuclear power team to support AI: ReportIn a theoretical circumstance where an LLM was trained on delicate banking information, for example, theres typically no other way for the AIs creator to find those files and delete them. Rather, AI devs use guardrails such as hard-coded triggers that prevent specific habits or support learning from human feedback (RLHF). In an RLHF paradigm, human assessors engage designs with the function of eliciting both wanted and unwanted habits. When the designs outputs are desirable, they get feedback that tunes the design toward that habits. And when outputs show unwanted habits, they get feedback designed to limit such habits in future outputs. Despite being “erased” from a models weights, the word “Spain” can still be conjured utilizing reworded triggers. Image source: Patil, et. al., 2023However, as the UNC scientists point out, this approach depends on people discovering all the flaws a design might show, and even when successful, it still does not “delete” the info from the model. Per the teams term paper: “A potentially much deeper shortcoming of RLHF is that a model might still know the delicate info. While there is much dispute about what designs really know it appears troublesome for a design to, e.g., have the ability to explain how to make a bioweapon however simply avoid answering questions about how to do this.” Ultimately, the UNC scientists concluded that even state-of-the-art design editing techniques, such as Rank-One Model Editing “fail to totally erase factual information from LLMs, as truths can still be extracted 38% of the time by whitebox attacks and 29% of the time by blackbox attacks.” The design the group used to conduct their research is called GPT-J. While GPT-3.5, among the base designs that power ChatGPT, was fine-tuned with 170 billion criteria, GPT-J just has 6 billion.Ostensibly, this means the problem of finding and getting rid of unwanted data in an LLM such as GPT-3.5 is tremendously more hard than doing so in a smaller sized design. The researchers were able to develop new defense approaches to secure LLMs from some “extraction attacks”– purposeful efforts by bad actors to utilize prompting to prevent a designs guardrails in order to make it output sensitive details However, as the researchers write, “the issue of deleting sensitive info might be one where defense methods are always playing catch-up to brand-new attack methods.”
Related Content
- How to use index funds and ETFs for passive crypto income
- Latest update — Former FTX CEO Sam Bankman-Fried trial [Day 13]
- Google sues scammers over creation of fake Bard AI chatbot
- Block Inc. Reports Increasing Bitcoin Awareness
- Ether price holds $1,820, but pro traders are skeptical about further gains